

Introducción
A medida que las empresas generan y reciben volúmenes cada vez mayores de datos de texto no estructurados, la capacidad de convertir esa información en información estructurada y utilizable se ha vuelto fundamental.
Los correos electrónicos, las facturas, los contratos, los tickets de soporte, los informes y los documentos escaneados contienen datos valiosos, pero sin los métodos de procesamiento adecuados, esos datos permanecen bloqueados en texto sin procesar.
Aquí es donde anotación de texto desempeña un papel fundamental.
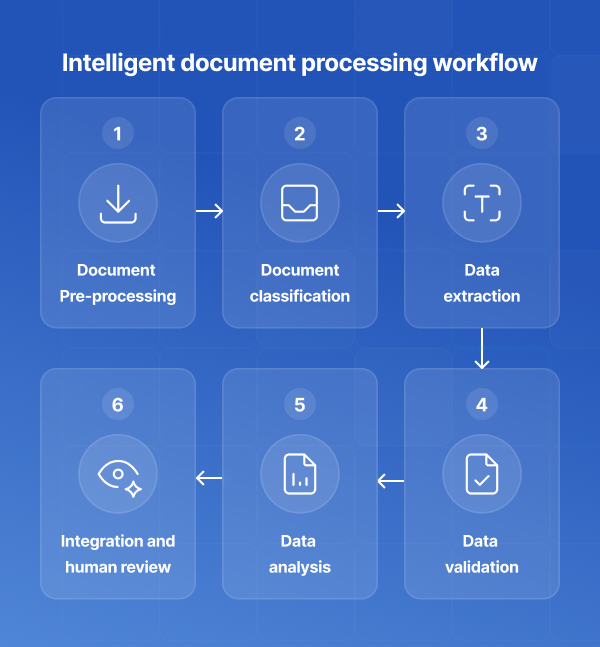
Desde la automatización de la extracción de datos de facturas hasta la alimentación procesamiento inteligente de documentos flujos de trabajo, la anotación de texto es una parte clave de muchas de las aplicaciones empresariales actuales impulsadas por la IA.
¿Qué es la anotación de texto?
Anotación de texto es el proceso de etiquetar o etiquetar datos de texto para darles una estructura y un significado que las máquinas puedan entender.
Estas etiquetas identifican elementos específicos del texto, como entidades, categorías, intención, sentimiento o relaciones entre palabras.
Este paso sirve como datos de entrenamiento para el aprendizaje automático y los sistemas de procesamiento del lenguaje natural
En términos prácticos, la anotación de texto transforma el texto sin procesar y no estructurado en conjuntos de datos estructurados que se pueden usar para entrenar, validar y mejorar los modelos de aprendizaje automático.
Sin datos anotados, los sistemas basados en el procesamiento del lenguaje natural no pueden reconocer patrones de manera confiable, extraer información clave ni hacer predicciones precisas.
Por ejemplo, durante un extracción de datos de facturas proceso, la anotación de texto puede implicar marcar los nombres de los proveedores, los números de factura, las fechas, las líneas de pedido y los montos totales.
En un Extracción de datos de órdenes de compra proceso, significa identificar campos de texto como fechas, números de referencia, nombres de compradores, nombres de bancos, etc.
Por lo tanto, cada anotación enseña al modelo cómo reconocer patrones similares en documentos nuevos e invisibles.
La anotación de texto es una parte fundamental del texto anotación de datos, una disciplina más amplia que incluye la preparación, el etiquetado y la validación de conjuntos de datos textuales para aplicaciones de IA. Se usa ampliamente en la automatización de documentos, la extracción de datos, los motores de búsqueda, los chatbots, el análisis de opiniones y la supervisión del cumplimiento.
A escala, la anotación de texto permite a las organizaciones:
- Entrene modelos de IA para comprender el lenguaje y los formatos de documentos específicos de la empresa
- Mejore la precisión de la extracción automatizada de datos
- Reduzca la dependencia de la entrada manual de datos
- Cree sistemas inteligentes que aprendan y mejoren continuamente con el tiempo
Al proporcionar contexto y estructura al texto, la anotación cierra la brecha entre el lenguaje humano y los datos legibles por máquina, lo que la convierte en la piedra angular del procesamiento de documentos moderno basado en la IA.
Tipos de anotación de texto
En el área de extracción de datos y Procesamiento de documentos mediante IA, la anotación de texto no es una técnica única, sino un conjunto de métodos que se utilizan para etiquetar los datos de texto en función de la tarea de procesamiento del lenguaje natural o aprendizaje automático prevista.
Cada tipo de anotación se centra en un aspecto diferente de la comprensión del lenguaje, desde la identificación de entidades clave hasta la captura de la intención o el sentimiento.
A continuación se muestran los tipos de anotación de texto más comunes y ampliamente utilizados.
Reconocimiento de entidades nombradas (NER)
El reconocimiento de entidades con nombre implica identificar y etiquetar entidades específicas en el texto. Estas entidades suelen pertenecer a categorías predefinidas, como nombres, fechas, ubicaciones, organizaciones o valores monetarios.
La NER es especialmente importante en los casos de uso de procesamiento de documentos y extracción de datos. Por ejemplo, en las facturas o los contratos, la anotación de entidades se puede utilizar para etiquetar:
- Nombres de empresas
- Números de factura
- Fechas y plazos
- Identificadores fiscales
- Montos en divisas
Al anotar estos elementos, los sistemas de inteligencia artificial aprenden a extraer automáticamente los campos obligatorios de grandes volúmenes de documentos con gran precisión.
Anotación de clasificación de texto
La anotación de clasificación de texto asigna categorías o etiquetas predefinidas a textos completos o segmentos de texto. En lugar de centrarse en palabras o frases individuales, este tipo de anotación analiza el significado general o el propósito del contenido.
Algunos ejemplos comunes son:
- Categorización de documentos (factura, recibo, contrato, correo electrónico)
- Enrutar los tickets de soporte por tema
- Clasificar los correos electrónicos como ventas, soporte o comunicación interna
La clasificación de texto se usa ampliamente en la automatización del flujo de trabajo, donde los documentos deben distribuirse, aprobarse o procesarse de manera diferente según su categoría.
Anotación de sentimientos
La anotación de sentimientos etiqueta el texto según el tono emocional o la opinión. Las categorías de sentimiento típicas incluyen las positivas, las negativas o las neutrales, aunque los sistemas más avanzados pueden utilizar etiquetas más detalladas.
Este tipo de anotación se aplica normalmente a:
- Comentarios y reseñas de clientes
- Respuestas a la encuesta
- Conversaciones de apoyo
Si bien el análisis de opiniones suele asociarse con el marketing y la experiencia del cliente, también puede ayudar a la detección de riesgos y a la priorización de problemas en los flujos de trabajo operativos.
Anotación de parte del discurso (POS)
La anotación de partes del discurso implica etiquetar cada palabra de una oración según su función gramatical, como sustantivo, verbo, adjetivo o adverbio.
La anotación POS ayuda a los modelos lingüísticos a entender la estructura y el contexto de las oraciones. A menudo se usa como un paso fundamental para tareas de procesamiento del lenguaje natural más avanzadas, como el reconocimiento de entidades y la extracción de relaciones.
Anotación de intención
La anotación de intenciones se centra en identificar el propósito subyacente detrás de un fragmento de texto. En lugar de clasificar de qué trata el texto, determina lo que el usuario o el documento intentan lograr.
Entre los ejemplos se incluyen:
- Identificación de solicitudes de pago en correos electrónicos
- Detección de la intención de aprobación o rechazo
- Reconocimiento de las solicitudes de acción en las comunicaciones con los clientes
La anotación de intenciones es particularmente valiosa para automatizar los procesos empresariales en los que las acciones deben activarse en función de la entrada de texto.
Anotación de relación y dependencia
Este tipo de anotación define cómo se relacionan las diferentes palabras o entidades entre sí dentro de una oración o documento. Captura dependencias como la propiedad, la causalidad o la jerarquía.
Por ejemplo, la anotación de relaciones puede ayudar a un sistema a comprender que un importe total está asociado a una factura específica o que una fecha de pago se aplica a una transacción en particular.
Ventajas de la anotación de texto en la extracción de datos
La anotación de texto es un factor fundamental para lograr precisión y escalabilidad extracción de datos.
Al proporcionar etiquetas estructuradas al texto sin procesar, la anotación permite a los sistemas de IA identificar, interpretar y extraer información relevante de los documentos con una mínima intervención humana.
Esta capacidad es especialmente valiosa en entornos en los que se deben procesar grandes volúmenes de documentos con velocidad, precisión y consistencia.
A continuación se muestran las principales ventajas de la anotación de texto en los flujos de trabajo de extracción de datos.
Mejora de la precisión de los datos
Los conjuntos de datos anotados enseñan a los modelos de aprendizaje automático qué información buscar exactamente y cómo interpretarla. Al etiquetar elementos como las fechas, los totales, las partidas o los detalles del proveedor, los modelos aprenden a distinguir los datos relevantes del ruido.
Esto lleva a:
- Menos errores de extracción
- Reducción de la clasificación errónea de los campos
- Menos revisiones de los informes debido a una mayor precisión
Las anotaciones precisas se traducen directamente en resultados confiables de extracción de datos, incluso cuando los documentos varían en formato o estructura.
Reducción de la entrada manual de datos
Una de las principales ventajas de la anotación de texto es su capacidad para eliminar el trabajo manual repetitivo. Una vez que los modelos se entrenan con los datos anotados, pueden extraer automáticamente la información clave de los documentos entrantes sin intervención humana.
Esto reduce significativamente:
- Tiempo dedicado a la entrada manual de datos
- Costos operativos relacionados con el trabajo administrativo
- Error humano
Como resultado, los equipos pueden centrarse en tareas de mayor valor en lugar de en la gestión rutinaria de documentos.
Procesamiento de documentos más rápido a escala
La anotación de texto permite a los sistemas de IA procesar documentos en segundos en lugar de minutos. Esta velocidad se vuelve crítica cuando se trata de grandes volúmenes de documentos, como facturas, recibos, contratos o formularios.
La extracción automatizada basada en datos anotados permite a las organizaciones:
- Procese miles de documentos simultáneamente
- Cumpla con plazos operativos ajustados
- Mantenga la coherencia del rendimiento durante los picos de carga de trabajo
La escalabilidad ya no está limitada por la capacidad humana.
Mejor manejo de datos no estructurados y semiestructurados
Muchos documentos empresariales no siguen plantillas estrictas. Los correos electrónicos, los PDF escaneados, los formularios manuscritos y las facturas de los proveedores suelen variar mucho en cuanto a diseño y redacción.
La anotación de texto ayuda a los modelos a aprender patrones contextuales en lugar de basarse únicamente en posiciones fijas. Esto permite extraer datos con precisión incluso cuando:
- Los diseños de los documentos cambian
- Los campos aparecen en diferentes ubicaciones
- El idioma y la terminología varían
Esta flexibilidad es esencial para los escenarios de procesamiento de documentos del mundo real.
Mejora continua del modelo
Los conjuntos de datos de texto anotado permiten que los sistemas de aprendizaje automático mejoren con el tiempo. A medida que se procesan nuevos documentos y se identifican casos extremos, se pueden agregar anotaciones adicionales para volver a entrenar los modelos.
Esto crea un ciclo de retroalimentación en el que:
- La precisión mejora con el uso
- Los nuevos formatos de documentos se aprenden más rápido
- El rendimiento de extracción se adapta a las necesidades específicas de la empresa
Con el tiempo, los sistemas de extracción de datos se vuelven más adaptables y precisos.
Mayor preparación para el cumplimiento y la auditoría
La extracción precisa de datos respaldada por la anotación de texto mejora la trazabilidad y la coherencia. Los campos extraídos se pueden validar, registrar y auditar más fácilmente que los datos introducidos manualmente.
Esto es particularmente importante para:
- Flujos de trabajo financieros y contables
- Informes reglamentarios
- Auditorías internas y mantenimiento de registros
La extracción consistente reduce los riesgos de cumplimiento y simplifica los procesos de auditoría.
TL; DR (demasiado tiempo; no lo leí)
En resumen, la anotación de texto convierte el texto sin procesar en datos estructurados y confiables para impulsar el procesamiento inteligente de documentos. Mejora la precisión, la velocidad, la escalabilidad y el cumplimiento, al tiempo que reduce el esfuerzo manual.
Anotación de texto para la extracción de datos: desafíos y soluciones por sector
Si bien la anotación de texto acelera la extracción de datos, su eficacia en el mundo real depende en gran medida del contexto industrial en el que se aplica.
Los equipos de contabilidad se ocupan de la precisión y el cumplimiento, los operadores hoteleros se ocupan de la velocidad y la variabilidad de los documentos, y las organizaciones de logística se enfrentan a desafíos de complejidad y conciliación.
A continuación, analizamos cómo la anotación de texto apoya la extracción de datos en tres sectores principales, examinando un caso de uso representativo para cada uno, los obstáculos más comunes encontrados y cómo se pueden abordar esos desafíos mediante un procesamiento de documentos inteligente e impulsado por la IA.
Tabla resumida (de un vistazo)
Contabilidad: extracción de datos de facturas para cuentas por pagar
En firmas de contabilidad, la anotación de texto se usa más comúnmente para extraer datos estructurados de las facturas de los proveedores como parte de los flujos de trabajo de cuentas por pagar.
El desafío no es solo el volumen, sino variabilidad.
Las facturas llegan en muchos formatos, a menudo en diferentes idiomas, y con una ubicación incoherente de los campos clave, como los números de factura, los importes de impuestos o los totales.
La extracción tradicional basada en reglas lucha en este entorno: incluso las pequeñas inconsistencias pueden llevar a publicaciones incorrectas, problemas de reconciliación o riesgos de cumplimiento.
Como resultado, los equipos de contabilidad deberán revisar y corregir manualmente los datos extraídos, lo que limitará las ganancias de eficiencia de la automatización.
Al aplicar la anotación de texto basada en inteligencia artificial a las entidades financieras, se puede entrenar a los modelos para que reconozcan los datos de las facturas en función del contexto y no de la posición.
Con el tiempo, el sistema aprende cómo los proveedores presentan la información y se adapta a los nuevos diseños.
Hostelería: facturas de proveedores y documentos de gastos
Empresas de hostelería como hoteles, grupos de restaurantes y agencias de viajes, dependen de una amplia gama de proveedores, cada uno de los cuales produce diferentes tipos de documentos.
Las facturas, los albaranes y los recibos suelen llegar escaneados o fotografías, a veces con una calidad de imagen deficiente. Esto dificulta la extracción uniforme de datos.
El desafío operativo se ve agravado por plazos.
Los equipos de hostelería necesitan datos de costos actualizados para administrar los márgenes, controlar el inventario y cerrar los períodos financieros a tiempo.
La anotación de texto combinada con el OCR permite a los operadores hoteleros extraer puntos de datos clave, como los nombres de los proveedores, los períodos de servicio, las cantidades y los totales, incluso de documentos no estructurados o de baja calidad. Al clasificar primero el tipo de documento y, a continuación, aplicar la lógica de anotación adecuada, el sistema se adapta a diversas entradas sin necesidad de plantillas rígidas. Esto permite un procesamiento más rápido, una mejor visibilidad de los costos y una menor carga de trabajo administrativo en todas las ubicaciones.
Logística: procesamiento de facturas de flete y documentos de transporte
La logística presenta uno de los entornos más complejos para la anotación de texto y la extracción de datos. Las facturas de flete suelen ser documentos de varias páginas que contienen partidas, recargos, referencias de envío y tarifas contractuales. Una sola factura puede estar relacionada con varias entregas, rutas o transportistas.
El principal desafío radica en asociar correctamente los datos extraídos con los envíos y sistemas correctos. Los errores en los números, las rutas o los totales de los envíos pueden provocar disputas de pago, retrasos en las aprobaciones y trabajos de conciliación manual entre los equipos de finanzas y operaciones.
La anotación de texto avanzada aborda esta complejidad al identificar no solo los campos individuales, sino también las relaciones entre ellos. Los identificadores de envío, los cargos y los detalles del servicio se pueden vincular en las páginas y secciones de un documento. Los modelos de extracción adaptados al contexto, formados en terminología y estructuras específicas de la logística, garantizan que los datos extraídos se alineen con los sistemas posteriores, como los ERP o las plataformas de gestión del transporte. Esto reduce las tasas de excepción y permite un procesamiento más confiable y automatizado de las facturas de flete.
Conclusión
La anotación de texto es esencial para una extracción de datos precisa y escalable, especialmente en las industrias con muchos documentos, como la contabilidad, la hostelería y la logística.
Cuando se aplica correctamente, permite a los sistemas de IA comprender el contexto, adaptarse a la variabilidad de los documentos y mejorar continuamente el rendimiento de la extracción.
Pruebe usted mismo la capacidad del sistema avanzado de extracción de datos de Procys mediante registrarse gratis (no se requiere cc).


