

Introduction
As businesses generate and receive increasing volumes of unstructured text data, the ability to convert that information into usable, structured insights has become critical.
Emails, invoices, contracts, support tickets, reports, and scanned documents all contain valuable data, but without the right processing methods, that data remains locked in raw text.
This is where text annotation plays a foundational role.
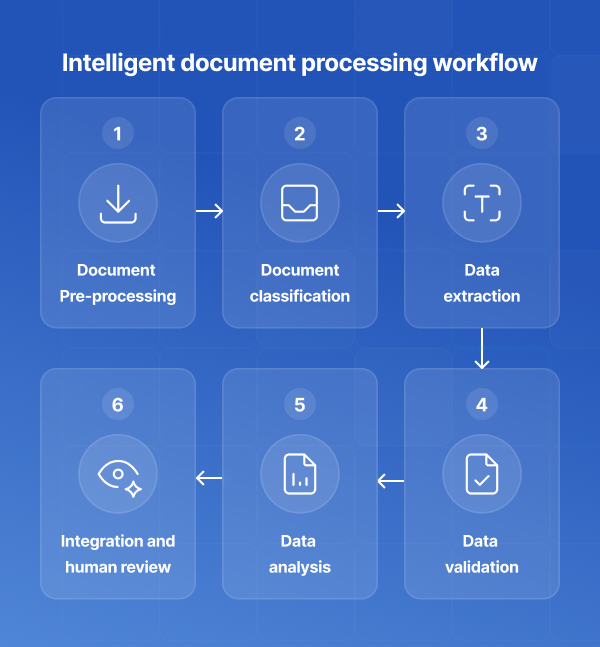
From automating invoice data extraction to powering intelligent document processing workflows, text annotation is a key part of many of today’s AI-driven business applications.
What is text annotation?
Text annotation is the process of labeling or tagging text data to give it structure and meaning that machines can understand.
These labels identify specific elements within text, such as entities, categories, intent, sentiment, or relationships between words.
This step serves as training data for machine learning and natural language processing systems
In practical terms, text annotation transforms raw, unstructured text into structured datasets that can be used to train, validate, and improve machine learning models.
Without annotated data, systems based on natural language processing cannot reliably recognize patterns, extract key information, or make accurate predictions.
For example, during an invoice data extraction process, text annotation may involve marking supplier names, invoice numbers, dates, line items, and total amounts.
In a Purchase Order data extraction process, it means identifying text fields like dates, reference numbers, buyer names, bank names, etc.
Thus, each annotation teaches the model how to recognize similar patterns in new, unseen documents.
Text annotation is a core part of text data annotation, a broader discipline that includes preparing, labeling, and validating textual datasets for AI applications. It is widely used in document automation, data extraction, search engines, chatbots, sentiment analysis, and compliance monitoring.
At scale, text annotation enables organizations to:
- Train AI models to understand business-specific language and document formats
- Improve the accuracy of automated data extraction
- Reduce reliance on manual data entry
- Build intelligent systems that continuously learn and improve over time
By providing context and structure to text, annotation bridges the gap between human language and machine-readable data, making it a cornerstone of modern AI-driven document processing.
Types of text annotation
In the area of data extraction and AI document processing, text annotation is not a single technique but a collection of methods used to label text data depending on the intended machine learning or natural language processing task.
Each annotation type focuses on a different aspect of language understanding, from identifying key entities to capturing intent or sentiment.
Below are the most common and widely used types of text annotation.
Named Entity Recognition (NER)
Named Entity Recognition involves identifying and labeling specific entities within text. These entities usually belong to predefined categories such as names, dates, locations, organizations, or monetary values.
NER is especially important in document processing and data extraction use cases. For example, in invoices or contracts, entity annotation can be used to tag:
- Company names
- Invoice numbers
- Dates and deadlines
- Tax IDs
- Currency amounts
By annotating these elements, AI systems learn how to automatically extract the required fields from large volumes of documents with high accuracy.
Text classification annotation
Text classification annotation assigns predefined categories or labels to entire texts or text segments. Instead of focusing on individual words or phrases, this type of annotation looks at the overall meaning or purpose of the content.
Common examples include:
- Categorizing documents (invoice, receipt, contract, email)
- Routing support tickets by topic
- Classifying emails as sales, support, or internal communication
Text classification is widely used in workflow automation, where documents must be routed, approved, or processed differently based on their category.
Sentiment annotation
Sentiment annotation labels text based on emotional tone or opinion. Typical sentiment categories include positive, negative, or neutral, although more advanced systems may use finer-grained labels.
This type of annotation is commonly applied to:
- Customer feedback and reviews
- Survey responses
- Support conversations
While sentiment analysis is often associated with marketing and customer experience, it can also support risk detection and issue prioritization in operational workflows.
Part-of-Speech (POS) annotation
Part-of-speech annotation involves labeling each word in a sentence according to its grammatical role, such as noun, verb, adjective, or adverb.
POS annotation helps language models understand sentence structure and context. It is often used as a foundational step for more advanced natural language processing tasks, including entity recognition and relationship extraction.
Intent annotation
Intent annotation focuses on identifying the underlying purpose behind a piece of text. Rather than classifying what the text is about, it determines what the user or document is trying to achieve.
Examples include:
- Identifying payment requests in emails
- Detecting approval or rejection intent
- Recognizing action requests in customer communications
Intent annotation is particularly valuable in automating business processes where actions must be triggered based on textual input.
Relationship and dependency annotation
This annotation type defines how different words or entities relate to each other within a sentence or document. It captures dependencies such as ownership, causality, or hierarchy.
For example, relationship annotation can help a system understand that a total amount is associated with a specific invoice or that a payment date applies to a particular transaction.
Benefits of text annotation in data extraction
Text annotation is a critical enabler of accurate and scalable data extraction.
By providing structured labels to raw text, annotation allows AI systems to identify, interpret, and extract relevant information from documents with minimal human intervention.
This capability is especially valuable in environments where large volumes of documents must be processed with speed, precision and consistency.
Below are the key benefits of text annotation in data extraction workflows.
Improved data accuracy
Annotated datasets teach machine learning models exactly what information to look for and how to interpret it. By labeling elements such as dates, totals, line items, or supplier details, models learn to distinguish relevant data from noise.
This leads to:
- Fewer extraction errors
- Reduced misclassification of fields
- Fewer reviews to reports due to higher accuracy
Accurate annotations directly translate into reliable data extraction results, even when documents vary in format or structure.
Reduced manual data entry
One of the primary advantages of text annotation is its ability to eliminate repetitive manual work. Once models are trained on annotated data, they can automatically extract key information from incoming documents without human input.
This significantly reduces:
- Time spent on manual data entry
- Operational costs tied to administrative work
- Human error
As a result, teams can focus on higher-value tasks rather than routine document handling.
Faster document processing at scale
Text annotation enables AI systems to process documents in seconds rather than minutes. This speed becomes critical when dealing with high document volumes such as invoices, receipts, contracts, or forms.
Automated extraction powered by annotated data allows organizations to:
- Process thousands of documents simultaneously
- Meet tight operational deadlines
- Maintain performance consistency during peak workloads
Scalability is no longer limited by human capacity.
Better handling of unstructured and semi-structured data
Many business documents do not follow strict templates. Emails, scanned PDFs, handwritten forms, and supplier invoices often vary widely in layout and wording.
Text annotation helps models learn contextual patterns rather than relying solely on fixed positions. This makes it possible to extract data accurately even when:
- Document layouts change
- Fields appear in different locations
- Language and terminology vary
This flexibility is essential for real-world document processing scenarios.
Continuous model improvement
Annotated text datasets allow machine learning systems to improve over time. As new documents are processed and edge cases are identified, additional annotations can be added to retrain models.
This creates a feedback loop where:
- Accuracy improves with usage
- New document formats are learned faster
- Extraction performance adapts to business-specific needs
Over time, data extraction systems become more adaptable and precise.
Stronger compliance and audit readiness
Accurate data extraction supported by text annotation improves traceability and consistency. Extracted fields can be validated, logged, and audited more easily than manually entered data.
This is particularly important for:
- Financial and accounting workflows
- Regulatory reporting
- Internal audits and record keeping
Consistent extraction reduces compliance risks and simplifies audit processes.
TL;DR (Too Long; Didn’t Read)
In summary, text annotation converts raw text into structured, reliable data to drive intelligent document processing. It improves accuracy, speed, scalability, and compliance while reducing manual effort.
Text annotation for data extraction: challenges and solutions by industry
While text annotation speeds up data extraction, its real-world effectiveness depends heavily on the industry context in which it is applied.
Accounting teams deal with accuracy and compliance, hospitality operators with speed and document variability, and logistics organizations with complexity and reconciliation challenges.
Below, we explore how text annotation supports data extraction in three core industries by examining a representative use case for each, the most common obstacles encountered, and how those challenges can be addressed through intelligent, AI-driven document processing.
Summary table (at a Glance)
Accounting: invoice data extraction for accounts payable
In accounting firms, text annotation is most commonly used to extract structured data from supplier invoices as part of accounts payable workflows.
The challenge is not volume alone, but variability.
Invoices arrive in many formats, often in different languages, and with inconsistent placement of key fields such as invoice numbers, tax amounts, or totals.
Traditional rule-based extraction struggles in this environment: even small inconsistencies can lead to incorrect postings, reconciliation issues, or compliance risks.
As a result, accounting teams will have to manually review and correct extracted data, limiting the efficiency gains of automation.
By applying AI-based text annotation to financial entities, models can be trained to recognize invoice data based on context rather than position.
Over time, the system learns how suppliers present information and adapts to new layouts.
Hospitality: supplier invoices and expense documents
Hospitality businesses such as hotels, restaurant groups, and travel operators rely on a wide range of suppliers, each producing different types of documents.
Invoices, delivery notes, and receipts often arrive as scans or photos, sometimes with poor image quality. This makes consistent data extraction difficult.
The operational challenge is compounded by deadlines.
Hospitality teams need up-to-date cost data to manage margins, control inventory, and close financial periods on time.
Text annotation combined with OCR allows hospitality operators to extract key data points such as supplier names, service periods, quantities, and totals even from low-quality or unstructured documents. By first classifying the document type and then applying the appropriate annotation logic, the system adapts to diverse inputs without requiring rigid templates. This enables faster processing, better cost visibility, and reduced administrative workload across locations.
Logistics: freight invoice and transport document processing
Logistics presents one of the most complex environments for text annotation and data extraction. Freight invoices are often multi-page documents containing line items, surcharges, shipment references, and contractual rates. A single invoice may relate to multiple deliveries, routes, or carriers.
The main challenge lies in correctly associating extracted data with the right shipments and systems. Errors in shipment numbers, routes, or totals can lead to payment disputes, delayed approvals, and manual reconciliation work between finance and operations teams.
Advanced text annotation addresses this complexity by identifying not only individual fields, but also the relationships between them. Shipment IDs, charges, and service details can be linked across pages and sections of a document. Context-aware extraction models, trained on logistics-specific terminology and structures, ensure that extracted data aligns with downstream systems such as ERPs or transportation management platforms. This reduces exception rates and enables more reliable, automated freight invoice processing.
Conclusion
Text annotation is essential for accurate and scalable data extraction, especially in document-heavy industries such as accounting, hospitality, and logistics.
When applied correctly, it allows AI systems to understand context, adapt to document variability, and continuously improve extraction performance.
Test the capability of Procys’ advanced data extraction system for yourself by signing up for free (no cc required).


